
The Modern IT Operations Challenge: Drowning in Data, Starving for Insight
The digital era has ushered in an unprecedented wave of technological advancement, fundamentally reshaping how businesses operate and deliver value. However, this transformation comes with a significant corollary: an explosion in the complexity of IT environments. Modern IT landscapes are intricate tapestries woven from hybrid and multi-cloud deployments, microservices architectures, containerization technologies like Kubernetes, a proliferation of Internet of Things (IoT) devices, and highly dynamic, ephemeral components. These sophisticated infrastructures generate an overwhelming volume, velocity, and variety of data – logs, metrics, traces, and events – that traditional IT operations tools and manual human oversight are increasingly ill-equipped to handle. Indeed, a staggering 85% of IT leaders identify this sheer volume of data as their most significant operational challenge, underscoring the pressing need for a paradigm shift.
This “data deluge” is not merely a technical inconvenience; it poses a substantial business risk. The inability to effectively manage, correlate, and interpret this vast sea of information directly translates into slower incident detection and resolution, increased system downtime, and consequently, a negative impact on customer experience, revenue streams, and brand reputation. In this high-stakes environment, two functions become paramount: Incident Management and Observability.
Incident Management traditionally refers to the set of processes and practices aimed at identifying, logging, categorizing, prioritizing, and resolving IT-related incidents – such as system outages, application failures, or network disruptions – as swiftly as possible to minimize their impact on business operations. Its focus has historically been reactive, responding to issues after they manifest.
Observability, on the other hand, is the capacity to measure and understand the internal states of a system by examining its outputs – primarily metrics, logs, and traces. Going beyond simple monitoring (which answers “if” a system is working), observability seeks to answer “why” a system might not be working as expected, providing the depth of insight needed for effective troubleshooting and continuous improvement.
The limitations of human capacity to process these massive data streams, coupled with the shortcomings of traditional, often siloed and rule-based, IT operations tools, have created an urgent need for a more intelligent, automated, and proactive approach. This is where Artificial Intelligence for IT Operations (AIOps) enters the stage, promising to revolutionize how organizations manage their increasingly complex digital estates. AIOps aims to transform IT operations from a state of reactive firefighting to one of proactive prevention, predictive insight, and automated remediation.
The ascent of AIOps is inextricably linked to the broader trend of digital transformation. As businesses worldwide accelerate their adoption of digital-first strategies, relying on agile and complex infrastructures like cloud computing and microservices to innovate and maintain a competitive edge, the operational burden escalates exponentially. AIOps emerges not just as a helpful tool, but as a critical enabler for sustaining this transformation. Without the advanced capabilities offered by AIOps to manage the resultant complexity, the very technologies driving business innovation could become bottlenecks, potentially stalling digital initiatives. Consequently, the adoption and maturity of AIOps can be seen as a key indicator of an organization’s overall digital maturity and its preparedness for future challenges.
Also Read: Why DevOps Engineers Are Irreplaceable in the AI Era
Deconstructing AIOps: The Engine of Intelligent Operations
At its core, AIOps represents the application of artificial intelligence and machine learning to the domain of IT operations. The widely recognized definition from Gartner states that AIOps combines big data and machine learning to automate IT operations processes, including event correlation, anomaly detection and causality determination. This definition succinctly captures the essence of AIOps: leveraging data and intelligent algorithms to bring automation and insight to complex IT environments.
The foundational pillars of AIOps are:
- Big Data: AIOps platforms are engineered to ingest, store, and process massive volumes of diverse IT data. This includes telemetry data such as logs, metrics, and traces, as well as event data, configuration management database (CMDB) information, IT service management (ITSM) tickets, and even unstructured data like chat conversations or documentation. This comprehensive data collection is the lifeblood of AIOps, providing the raw material for analysis.
- Machine Learning (ML): Advanced ML algorithms form the intelligent core of AIOps. These algorithms are employed to automatically learn patterns from historical and real-time data, identify anomalies that deviate from normal behavior, correlate seemingly disparate events to uncover underlying relationships, predict potential future issues, and even suggest or automate remediation actions. Techniques range from statistical analysis and pattern recognition to more sophisticated approaches like deep learning.
- Artificial Intelligence (AI): AI serves as the overarching discipline that encompasses ML, along with other cognitive technologies such as Natural Language Processing (NLP). NLP, for example, can enable AIOps systems to understand human language in tickets or documentation, or allow operators to query systems using natural language commands.
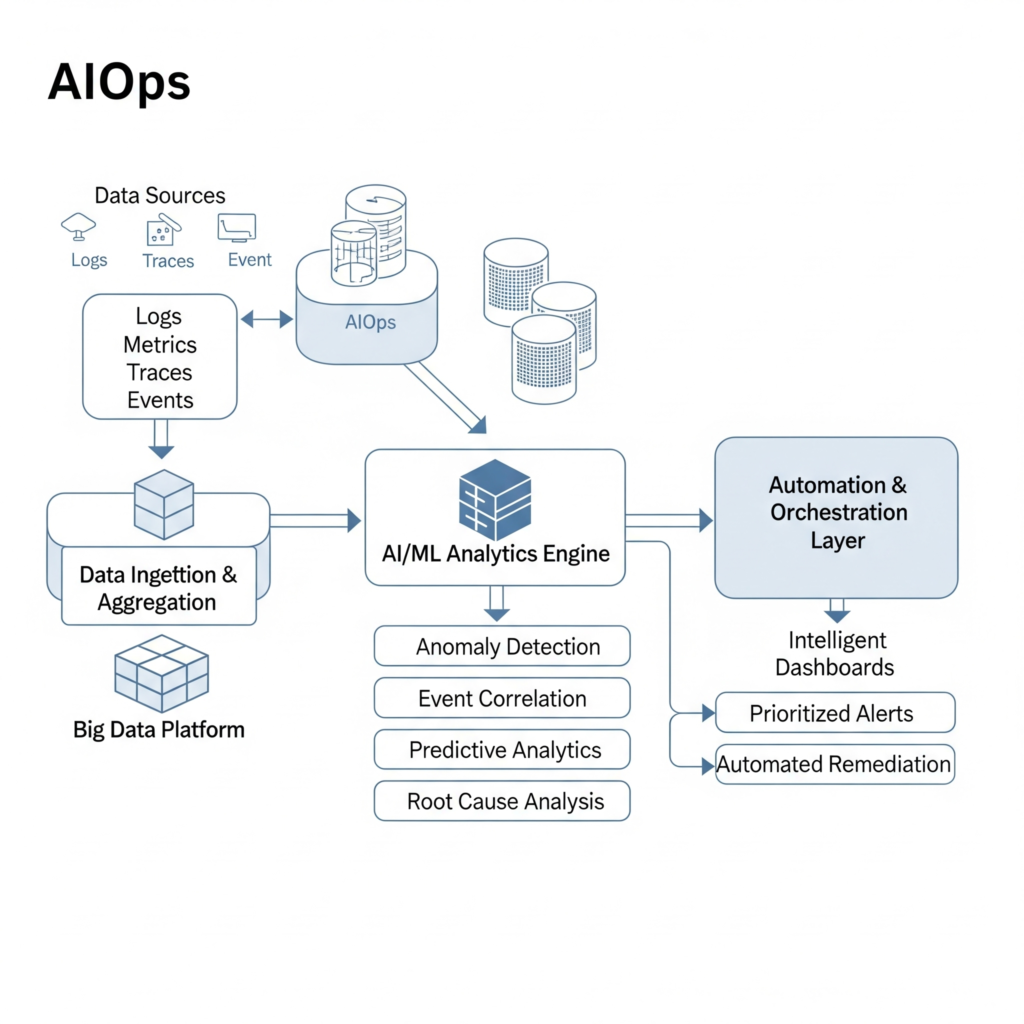
The operational workflow of an AIOps platform typically follows a cyclical process of data ingestion, analysis, and action, often described by models like “Observe, Engage, Act” :
- Observe/Ingest: The first stage involves collecting and aggregating data from a multitude of siloed IT operations tools and diverse data sources. This data is often normalized and centralized within the AIOps platform, breaking down traditional data silos and creating a unified data foundation.
- Engage/Analyze: Once data is ingested, AIOps applies its AI/ML engine to analyze the data in real-time and historically. This stage includes critical functions like intelligent event correlation to reduce alert noise, advanced anomaly detection to spot unusual behavior, pattern recognition to understand system dynamics, predictive analytics to forecast potential issues, and root cause analysis to pinpoint the source of problems.
- Act/Automate: Based on the insights generated during the analysis phase, the AIOps platform facilitates action. This can range from generating highly contextualized and prioritized alerts for human operators, suggesting specific remediation steps, automatically creating incident tickets in ITSM systems, or triggering automated responses and self-healing actions to resolve issues without manual intervention.
It’s important to recognize that AIOps is not merely about automating existing IT tasks with greater efficiency. It is about enabling entirely new capabilities that were previously impractical or impossible at scale. While traditional IT operations could perform rudimentary event correlation or set static thresholds for anomaly detection, AIOps, by harnessing the combined power of big data and advanced machine learning, executes these functions with a level of speed, scale, and accuracy that far surpasses human capabilities. Furthermore, sophisticated capabilities such as true predictive analytics based on complex pattern recognition across disparate datasets, and proactive remediation workflows, were largely aspirational before the advent of AIOps.
The “Act” phase of the AIOps lifecycle, particularly the automation of remediation and the move towards self-healing systems, represents a significant operational and cultural paradigm shift towards autonomous operations. This delegation of decision-making and execution to intelligent systems has profound implications for the roles and skillsets required within IT departments. IT professionals are increasingly transitioning from manual operators to supervisors, strategists, and developers of these autonomous systems. This evolution necessitates new competencies in areas such as AI, machine learning, data science, and automation engineering, alongside robust governance frameworks and a cultivated trust in AI-driven actions.
Incident Management: From Reactive Firefighting to Proactive Prevention
Traditional Incident Management, while structured, has long been plagued by inefficiencies in the face of increasingly complex IT environments. The typical lifecycle involves identifying an issue, logging it (often as a ticket), categorizing its nature, prioritizing it based on impact and urgency, and then responding – a phase that includes diagnosis, potential escalation to specialized teams, communication with stakeholders, resolution of the root cause, and service recovery. Finally, the incident is formally closed.
However, this conventional approach is fraught with challenges:
- Alert Fatigue and Noise: IT operations teams are often inundated with an overwhelming volume of alerts from numerous monitoring tools. A significant percentage of these alerts can be false positives (over 52%) or redundant notifications (64%) stemming from the same underlying issue. This constant barrage leads to “alert fatigue,” where operators become desensitized and may inadvertently ignore or miss genuinely critical alerts, posing a substantial business risk.
- Manual, Time-Consuming Root Cause Analysis (RCA): When an incident occurs, engineers typically embark on a painstaking manual process of sifting through logs, metrics, and event data from disparate, often siloed, tools. This “war room” scenario can take hours, or even days, to pinpoint the actual root cause of the problem.
- High Mean Time to Detect (MTTD) and Mean Time to Resolution (MTTR): The manual nature of alert investigation and root cause analysis directly contributes to prolonged MTTD (the average time taken to detect an incident) and MTTR (the average time taken to resolve an incident). These delays extend service disruptions, jeopardize Service Level Agreements (SLAs), and negatively impact business continuity and customer satisfaction.
AIOps offers a transformative solution to these persistent pain points, revolutionizing the incident management lifecycle :
- Intelligent Alert Correlation and Noise Reduction: AIOps platforms employ machine learning algorithms to analyze the relationships between vast streams of events and alerts from diverse sources. They can automatically group related alerts that stem from a single underlying problem, suppress duplicate notifications, and filter out irrelevant noise. This capability transforms a torrent of hundreds or thousands of raw alerts into a small number of actionable, high-fidelity incidents, allowing teams to focus on what truly matters.
- Automated and Accelerated Root Cause Analysis (RCA): By correlating data across logs, metrics, traces, and system topology information, AIOps can rapidly identify the likely root cause of an incident. It analyzes dependencies between components, contextual data, and the sequence of events to provide probable causes, often with supporting evidence, significantly faster than manual troubleshooting efforts. This is a cornerstone of AIOps’ value proposition.
- Predictive Incident Detection: A key differentiator of AIOps is its ability to move beyond reactive responses. By analyzing historical data patterns and real-time trends, AIOps can identify anomalies and predict potential issues before they escalate to impact users or trigger conventional threshold-based alerts. This proactive stance allows teams to intervene and prevent outages or performance degradations.
- Automated Remediation and Self-Healing: For known issues with well-defined resolution procedures, AIOps can orchestrate automated remediation. This involves triggering predefined runbooks, scripts, or automation workflows to execute corrective actions, such as restarting a failed service, scaling resources up or down, or reverting a problematic configuration change, often without requiring human intervention. This capability is pivotal in achieving truly resilient and autonomous operations.
The following table provides a comparative overview:
| Metric/Process | Traditional Approach | AIOps-Enabled Approach | Impact |
|---|---|---|---|
| Alert Volume | High, Noisy, Uncorrelated | Significantly Reduced, Contextualized, Prioritized | Reduced Alert Fatigue, Faster Triage |
| Incident Detection | Reactive, Static Thresholds | Proactive, Dynamic Anomaly Detection | Earlier Detection, Potential Outage Prevention |
| Root Cause Analysis Time | Hours/Days, Manual Correlation | Minutes, Automated Correlation & Causality Determination | Drastically Reduced MTTR |
| Remediation | Manual, Scripted | Automated Workflows, Self-Healing | Faster Resolution, Reduced Human Error, Increased Consistency |
| Data Utilization | Siloed, Often Underutilized | Unified, Analyzed Holistically | Deeper Insights, Continuous Learning, Better Operational Understanding |
| MTTD (Mean Time To Detect) | High | Significantly Reduced | Minimized “Blast Radius” of Incidents |
| MTTR (Mean Time To Resolve) | High | Significantly Reduced | Improved Service Availability, Reduced Business Impact |
| Human Effort | Intensive, Repetitive, Prone to Burnout | Focused on Strategic Tasks, Oversight, and Complex Issues | Increased Efficiency, Improved Team Morale, Focus on Innovation |

The impact of AIOps extends beyond mere speed; it fundamentally alters the nature of incident management. Traditional processes are predominantly detective, focused on reacting to failures that have already occurred. In contrast, AIOps, with its predictive capabilities and automated remediation, aims to prevent incidents from happening in the first place or to resolve them autonomously before users are even aware of a problem. This represents a significant paradigm shift from reactive problem-solving to proactive and preventative operational management.
Furthermore, the tangible benefits of reduced MTTR and diminished alert fatigue brought about by AIOps have a profound and often underestimated positive effect on IT team morale and retention. The relentless pressure of constant firefighting and the cognitive load of sifting through endless alerts are major contributors to stress and burnout within IT operations teams. By alleviating these burdens, AIOps frees up valuable engineering time and cognitive capacity. This allows teams to redirect their efforts towards more strategic, value-adding initiatives, such as system improvement, innovation, and automation development, ultimately fostering higher job satisfaction and a more forward-looking IT culture. This human capital advantage is a significant, yet frequently overlooked, outcome of successful AIOps adoption.
Observability: Achieving True System Understanding with AIOps
Observability is founded on three primary types of telemetry data, often referred to as its pillars: metrics, logs, and traces.
- Metrics are numerical, time-series data points that provide a quantitative, aggregated view of system health and performance over time. Examples include CPU utilization, memory consumption, error rates, and request latency. Metrics help answer the “what” – what is the current state or performance level of a system or component.
- Logs are immutable, timestamped records of discrete events that have occurred within a system or application. They provide detailed, contextual information about specific occurrences, such as errors, transactions, or user activities. Logs help answer the “why” – why did a particular event or failure happen.
- Traces (or distributed traces) capture the end-to-end journey of a single request or transaction as it propagates through various services and components in a distributed system. Each step in the journey is a “span.” Traces are crucial for understanding request flows, identifying performance bottlenecks, and pinpointing error sources in microservices architectures. They help answer the “where” and “how” – where did a request slow down or fail, and how did the system components interact during its processing.
Traditionally, these pillars, while providing valuable data, often require significant manual effort to correlate and interpret, especially given the sheer volume of data generated by modern systems.
The conventional approach to observability, despite its strengths, faces several limitations in complex, dynamic environments :
- Data Silos: Observability data (metrics, logs, traces) often resides in separate, specialized tools that don’t easily share information. This fragmentation makes it challenging to achieve a holistic view of system behavior and to correlate events across different data types.
- Reactive Problem-Solving: While traditional observability tools can indicate that something is wrong (e.g., a metric has breached a threshold), they often fall short in quickly explaining why it happened or guiding teams to the root cause without extensive manual investigation. This leads to a predominantly reactive stance.
- Tool Sprawl and Data Overload: The complexity of modern IT stacks often leads to “tool sprawl,” with organizations using numerous monitoring and observability tools. The combined data output can be overwhelming, leading to alert fatigue and making laborious, manual analysis a necessity.
- Limited Automated Root Cause Analysis: While providing visibility into system behaviors, traditional observability solutions rarely connect all the disparate data points automatically to pinpoint the underlying cause of incidents. Teams are often left investigating symptoms rather than addressing the core issue directly.
AIOps significantly enhances and supercharges observability by applying intelligence and automation to these data streams :
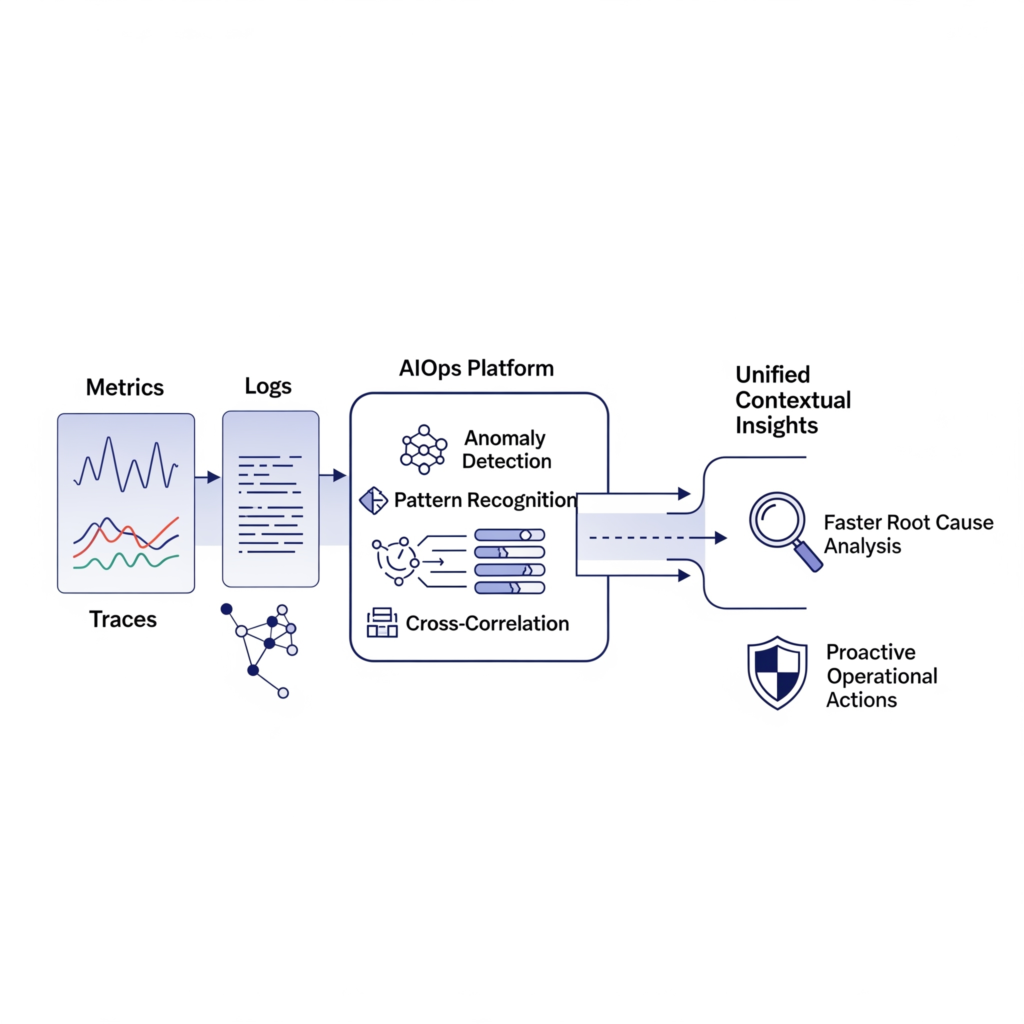
- Advanced Anomaly Detection: AIOps leverages machine learning to establish dynamic baselines of normal behavior for countless metrics and log patterns across the IT environment. It can then automatically identify subtle deviations, outliers, and anomalies that might indicate emerging problems, often before static, predefined thresholds are breached. For instance, Splunk’s AIOps capabilities utilize trending algorithms (monitoring a single KPI against its past behavior) and cohesive algorithms (looking at groups of KPIs expected to behave similarly). Azure Monitor offers Kusto Query Language (KQL) functions with built-in machine learning for time series analysis and anomaly detection.
- Cross-Domain Pattern Recognition: AIOps excels at correlating information not just within a single data type, but across all three pillars of observability (metrics, logs, and traces) and often integrates data from other sources like CMDBs, ITSM tickets, and network topology maps. This holistic analysis uncovers complex patterns, hidden dependencies, and causal relationships that would be virtually invisible to human analysis or siloed monitoring tools, providing a truly unified view of system health and behavior.
- Contextual Data Enrichment: AIOps platforms enrich raw telemetry data by adding crucial context. This can include business context (e.g., which business service is affected), topological information (e.g., service dependencies, infrastructure relationships), historical incident data, and even unstructured semantic data from sources like chat conversations or technical documentation. For example, Datadog’s AIOps enriches telemetry with semantic data from chat logs, call transcripts, and code repositories to provide deeper context. ScienceLogic emphasizes the importance of topology-based analytics for understanding relationships. This enrichment transforms raw data into meaningful, actionable insights.
- Enhancing Distributed Tracing Analysis in Microservices: In complex microservice environments, the volume of trace data can be immense. AIOps can analyze these vast datasets to automatically identify performance bottlenecks, error sources, and critical service dependencies. This makes distributed tracing more scalable and its insights more readily actionable, helping teams understand the intricate interactions within their applications.
AIOps effectively transforms observability from what can be a passive data-gathering and manual analysis practice into an active, intelligent system that actively drives understanding and facilitates informed action. While traditional observability provides the necessary raw data , it is AIOps that furnishes the intelligence to interpret this data at scale, identify what is truly significant, and weave disparate signals into a coherent and actionable narrative of system behavior and health. This evolution moves IT operations beyond merely asking “Can I see what’s happening?” to confidently answering “Do I understand why it’s happening and what needs to be done next, often automatically?”
The contextual enrichment provided by AIOps is particularly powerful because it bridges the often-significant gap between raw IT metrics and their actual business impact. By linking technical anomalies or performance degradations – detected through metrics, logs, and traces – to specific business services, user experiences, and potential revenue implications, AIOps enables IT teams to prioritize issues based on their true business significance rather than just technical severity. This capability, as highlighted by industry analysts like Forrester, elevates IT operations from being perceived as a cost center to becoming a strategic partner in achieving overarching business objectives. It allows for more informed decision-making, ensuring that resources are focused on issues that matter most to the business.
The AIOps-Observability Synergy: A Virtuous Cycle for IT Excellence
The relationship between AIOps and observability is not one of replacement, but of powerful synergy. They are two sides of the same coin, working together to deliver unprecedented levels of insight and control over complex IT environments.
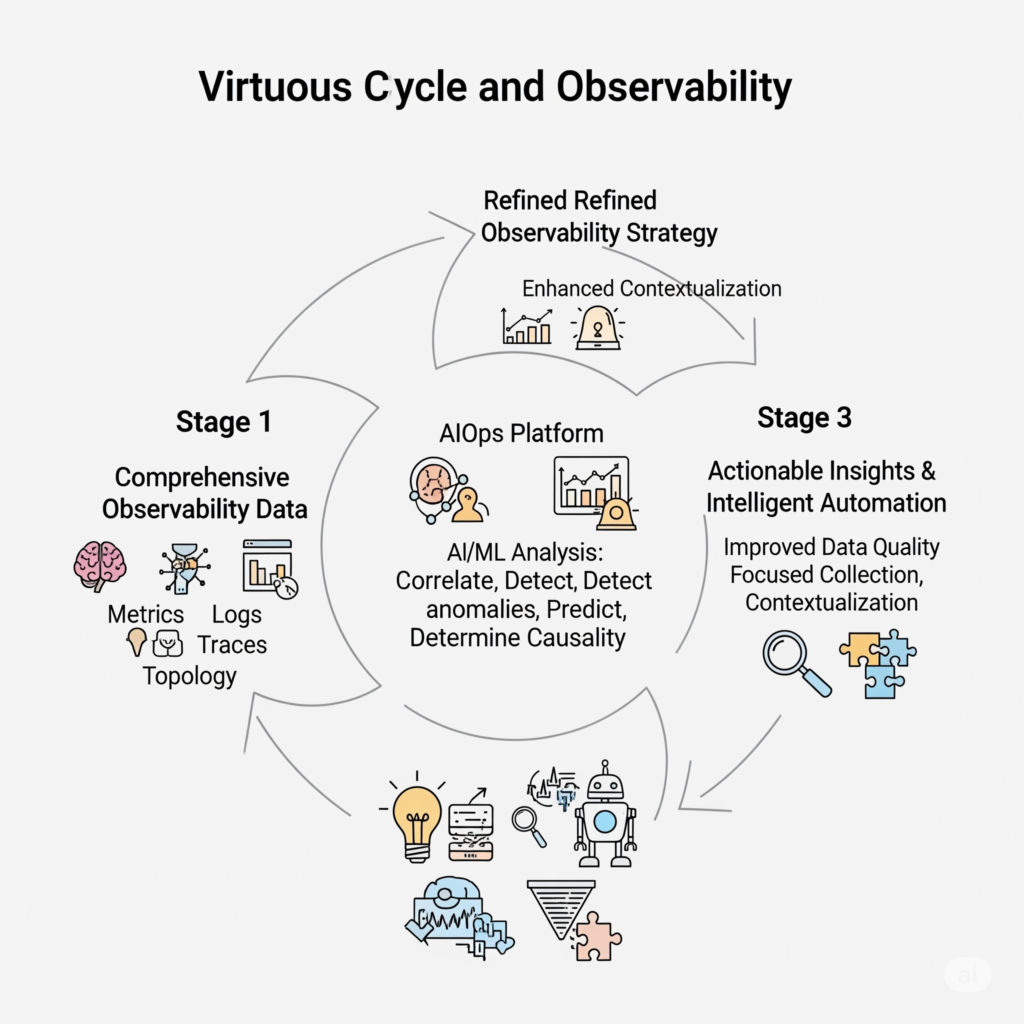
AIOps fundamentally relies on the rich, high-fidelity data provided by a robust observability practice. Metrics, logs, and traces are the essential fuel that powers AIOps platforms, enabling their AI/ML engines to learn, analyze, and act. Without comprehensive and high-quality observability data, AIOps algorithms cannot accurately detect anomalies, correlate events, predict future issues, or determine root causes effectively. The adage “garbage in, garbage out” is particularly pertinent here; the quality, completeness, and context of observability data are paramount for the success of any AIOps initiative.
Conversely, AIOps-driven insights play a crucial role in refining and optimizing observability strategies. By analyzing which data points are most indicative of problems or most valuable for prediction, AIOps can help identify gaps in current observability coverage. It can highlight areas where data is insufficient for effective analysis or where the signal-to-noise ratio is poor. These insights can guide IT teams on which metrics are most critical to track with higher granularity, which log sources require more detailed structuring or parsing, or where distributed tracing needs to be implemented or enhanced to provide better visibility into critical transaction flows. This creates an intelligent feedback loop, where AIOps helps to continuously improve the quality and focus of the data it consumes.
The combination of comprehensive data from mature observability practices and the intelligent analysis and automation capabilities of AIOps enables organizations to achieve true full-stack visibility. This holistic understanding spans the entire IT landscape, from underlying infrastructure (servers, networks, storage) through middleware and platforms (databases, messaging queues, container orchestrators) to applications and, ultimately, the end-user experience. This synergy is instrumental in moving organizations towards a state of proactive control, where potential issues are anticipated and mitigated before they impact services, rather than being addressed only after failures occur. Forrester emphasizes that successful AIOps and observability initiatives are not one-off projects but should support iterative processes with tight feedback loops, fostering continuous improvement.
This dynamic interplay creates a virtuous cycle: better, more contextualized observability data fuels more accurate and actionable AIOps insights. These insights, in turn, lead to more targeted data collection and refined observability strategies, further enhancing the quality of data fed into the AIOps platform.
The synergy between AIOps and observability extends beyond the purely technical realm; it has significant organizational implications. By providing a unified platform that consumes and correlates comprehensive observability data, AIOps establishes a single source of truth for IT operations. When diverse teams such as DevOps, Site Reliability Engineering (SRE), and traditional IT Operations are all working from the same correlated, intelligent insights, communication during incidents becomes far more effective. This shared understanding helps to break down traditional silos, reduce “blame games,” and foster a more collaborative and efficient operational culture. This cultural benefit is a key enabler of agility and responsiveness.
Ultimately, mature AIOps and observability practices can evolve into a significant competitive differentiator for businesses. Organizations that successfully master this synergy are better positioned to achieve higher service reliability and availability, accelerate their innovation cycles by reducing the time spent on reactive firefighting and empowering development teams , and deliver superior customer experiences. In today’s digital-first economy, these operational efficiencies and service quality improvements translate directly into tangible market advantages. The ability to “detect critical technical problems before they impact business objectives,” as highlighted by Gartner, is not just an IT goal but a powerful business enabler.
AIOps in Action: Real-World Success Stories and Use Cases
The transformative potential of AIOps is best illustrated through real-world applications where organizations have achieved measurable improvements in their IT operations and business outcomes.
Case Study 1: Financial Services – KFin Technologies Achieves 90% MTTR Reduction KFin Technologies, operating in the data-intensive financial services industry, faced challenges in managing the performance of its critical databases and applications. By implementing ManageEngine Applications Manager, an AIOps-capable monitoring solution, they gained end-to-end insight into essential transactions, identified slow-performing queries, and leveraged AI-powered smart alerts. The results were striking: a 90% reduction in Mean Time to Resolution (MTTR) for incidents. The company also saw a significant decrease in Severity 1 (S1) incidents, freeing up their IT team to focus on innovation rather than constant firefighting. The ability to obtain precise answers about performance anomalies also helped optimize the overall customer experience. This case study powerfully demonstrates the direct impact of AIOps on a critical operational KPI and its flow-on benefits to business agility.
Case Study 2: FinTech Firm Slashes MTTR by 70% and Accelerates Resolution Another FinTech firm sought to improve service reliability. Through a combination of DevOps consulting and automation, leveraging technologies often integral to an AIOps ecosystem (such as Kubernetes for orchestration, Prometheus for metrics, Grafana for visualization, Jenkins for CI/CD, and AWS Lambda for serverless functions), they achieved remarkable results. The initiative led to a 70% reduction in MTTR, an 85% acceleration in overall issue resolution, and a 40% reduction in associated operational costs. This example highlights how AIOps principles, when embedded within modern operational practices and toolchains, can yield substantial improvements in efficiency and cost-effectiveness.
Case Study 3: Tecsys Reduces Alert Incidents by 69% with Datadog AIOps Tecsys, a supply chain management software company, was grappling with alert noise and the challenge of multiple redundant incidents stemming from the same root cause, which overwhelmed their Site Reliability Engineers (SREs). By implementing Datadog’s Event Management, an AIOps feature, they were able to effectively correlate alerts, cut through the noise, and consolidate multiple notifications into single, actionable incidents within their incident management tool. This streamlined approach resulted in a 69% reduction in alert incidents, significantly simplifying the work of their SRE team and improving operational focus.
Beyond these specific examples, AIOps delivers value across a wide spectrum of use cases:
- Proactive Capacity Optimization: AIOps analyzes historical resource utilization patterns and current trends to predict future capacity needs for servers, storage, and network bandwidth. This allows organizations to proactively scale resources, identify and reclaim wasted capacity, and optimize infrastructure investments, leading to significant cost savings and assured performance. For instance, AIOps can predict impending disk space depletion based on write patterns, allowing intervention before services are impacted.
- Enhanced Application Performance Monitoring (APM): AIOps ingests telemetry from APM tools, correlating application performance data (like response times, error rates, transaction traces) with underlying infrastructure metrics and logs. This provides deeper insights into application behavior, identifies complex dependencies, and pinpoints performance bottlenecks more accurately, especially in distributed and cloud-native application architectures.
- Cloud Cost Optimization: In hybrid and multi-cloud environments, AIOps helps control expenditure by automating workload management, optimizing resource allocation based on demand, identifying underutilized or orphaned cloud assets, and providing recommendations for right-sizing instances. This leads to more efficient use of cloud services and reduced operational costs.
- Anomaly Detection in Streaming Services (e.g., Netflix): Companies like Netflix leverage AIOps principles to detect irregularities in their streaming services in real-time. This helps minimize downtime, ensure a consistent user experience, and proactively address issues that could affect millions of subscribers. Netflix’s “Simian Army,” which includes tools like Chaos Monkey to proactively test system resilience, is an advanced example of this proactive approach.
- Automated Root Cause Analysis (General): This remains a primary and highly valued use case across all industries. AIOps enables IT teams to rapidly move beyond merely observing symptoms to determining the actual underlying causes of system problems, significantly reducing diagnostic time and effort.
The diverse applications of AIOps can be summarized as follows:
| Use Case | Description | Key Benefits | Relevant AIOps Capabilities |
|---|---|---|---|
| Intelligent Alert Correlation & Noise Reduction | Automatically groups related alerts, suppresses duplicates, filters noise. | Reduced Alert Fatigue, Faster Triage, Focus on Critical Issues. | Event Correlation, Machine Learning, Topology Awareness. |
| Automated Root Cause Analysis (RCA) | Pinpoints underlying causes of incidents by analyzing dependencies, contextual data, and event sequences. | Drastically Reduced MTTR, Improved Reliability, Less Manual Investigation. | AI/ML Analytics, Dependency Mapping, Log/Metric/Trace Correlation, Causality Determination. |
| Predictive Anomaly Detection | Identifies subtle deviations from normal behavior patterns before they impact users or trigger static alerts. | Proactive Issue Prevention, Reduced Downtime, Early Warning of Problems. | Machine Learning, Dynamic Baselining, Statistical Analysis, Pattern Recognition. |
| Automated Remediation & Self-Healing | Triggers predefined runbooks or automated workflows to resolve known issues without human intervention. | Faster Resolution, Reduced Human Error, Increased System Resilience, 24/7 Automated Response. | Automation Engines, Orchestration, Runbook Automation, AI-Driven Decision Making. |
| Proactive Capacity Optimization | Analyzes historical usage and trends to predict future resource needs and identify waste. | Cost Savings, Performance Assurance, Efficient Resource Allocation, Avoidance of Capacity-Related Outages. | Predictive Analytics, Trend Analysis, Machine Learning, Resource Monitoring. |
| Cloud Cost Management | Optimizes resource allocation, identifies underutilized cloud assets, and automates workload management in cloud environments. | Reduced Cloud Spend, Improved ROI on Cloud Investments, Efficient Cloud Operations. | Cloud Resource Monitoring, Usage Analytics, Automation, Cost Optimization Algorithms. |
| Enhanced Application Performance Monitoring (APM) | Ingests APM data for deeper insights into application behavior, dependencies, and performance bottlenecks. | Improved Application Stability, Better User Experience, Faster Troubleshooting of Application Issues. | APM Data Ingestion, Trace Analysis, Dependency Mapping, Performance Baselining. |
| Security Threat Detection | Analyzes logs and network traffic for patterns indicative of security threats, complementing dedicated security tools. | Early Detection of Security Incidents, Reduced Risk of Breaches, Enhanced Security Posture. | Log Analysis, Network Traffic Analysis, Anomaly Detection, Pattern Recognition (applied to security data). |
The success stories and diverse use cases consistently demonstrate that the most impactful AIOps initiatives are those directly addressing core business pain points such as service downtime, high operational costs, and compromised customer satisfaction. The ability of AIOps to deliver quantifiable improvements in critical metrics like MTTR, alert volume, and operational efficiency provides a strong justification for investment, positioning AIOps not just as a technological advancement but as a solution to pressing business challenges.
Furthermore, a common thread in many successful AIOps deployments is a phased or iterative approach to adoption. Organizations often begin by targeting specific, high-impact use cases – such as KFin Technologies focusing on database and application performance or Tecsys addressing alert correlation. This strategy allows them to demonstrate value quickly, build internal expertise and confidence in AIOps capabilities, and then progressively scale these capabilities to other areas of their IT operations. Such an iterative approach aligns well with agile principles, mitigates the risks associated with large-scale technology rollouts, and fosters a culture of continuous learning and improvement.
Visualizing Intelligence: The Power of AIOps Dashboards
AIOps platforms transform vast quantities of complex data into actionable intelligence, and a critical component of this transformation is the AIOps dashboard. These dashboards serve as the primary interface for IT operations teams, SREs, and other stakeholders to visualize system health, understand emerging issues, and make informed decisions rapidly.
Key features commonly found in AIOps dashboards include:
- Unified View and Service Health Scores: A central design principle is the consolidation of data from disparate sources (metrics, events, logs, traces, topology, incidents, vulnerabilities) into a single, coherent pane of glass. This often includes high-level service health scores, often visualized using intuitive color-coding (e.g., red, yellow, green), and heatmaps that provide an at-a-glance overview of the status of various business services and their underlying components. The BMC Helix Overview page, for example, provides such a consolidated dashboard.
- Anomaly Visualization: Dashboards effectively display anomalies by overlaying them on metric charts, highlighting deviations from dynamically established baselines, and often presenting anomaly scores to indicate the severity or unusualness of an event. New Relic, for instance, offers capabilities for instant anomaly detection that can be visualized.
- Correlated Events and “Situations”: Instead of displaying raw alerts, AIOps dashboards group related alerts and events into consolidated “situations,” “incidents,” or “stories.” This significantly reduces noise and presents a clearer picture of the actual problem and its scope. Moogsoft’s platform, for example, focuses on correlating alerts into manageable incidents , and the BMC Situations page provides a dedicated view for these correlated event groups.
- Topology and Dependency Mapping: Visualizing the relationships between configuration items (CIs), applications, services, and infrastructure components is crucial. Topology maps help users understand the potential impact radius of an incident and trace dependencies to identify root causes more effectively.
- Predictive Insights and Warnings: Advanced AIOps dashboards display forecasts of potential future issues, such as impending capacity shortfalls, service degradations, or potential outages, often with a confidence score or likelihood percentage. This enables proactive intervention. The BMC Predictions page is an example of this capability.
- Root Cause Analysis Display: When an incident occurs, dashboards present the likely root cause(s) identified by the AIOps engine, along with supporting evidence (e.g., key log snippets, critical metric deviations, relevant configuration changes) in a clear and understandable format.
- Key Performance Indicators (KPIs): Dashboards track and display critical operational KPIs, such as MTTR, MTTD, alert reduction percentages, service availability, and automation rates, allowing teams to measure the effectiveness of their AIOps strategy and overall operational performance.
These features collectively empower IT teams to make quicker, more data-driven decisions and to shift towards proactive interventions. An effective AIOps dashboard provides an immediate, intuitive understanding of the current system status and any emerging issues. It enables faster triage and prioritization of incidents by highlighting what’s most critical. By offering a common operational picture, it supports collaborative troubleshooting among different teams. Most importantly, by presenting predictive warnings, it facilitates proactive actions to prevent problems before they impact users.
It is crucial to understand that the most effective AIOps dashboards are not merely passive displays of data; they are interactive tools designed to tell a coherent story and guide users toward appropriate actions. The best dashboards, as implied by the features offered by leading AIOps solutions , go beyond raw data presentation. They synthesize complex information, intelligently highlight what is critical (e.g., top impacted business services, primary situations needing attention), provide essential context (such as service topology or historical performance trends), and in many cases, even suggest or link to recommended next steps or automated remediation playbooks. In essence, they transform a deluge of operational data into focused, actionable intelligence specifically tailored for human operators.
Looking ahead, the evolution of AIOps dashboards will likely see deeper integration of natural language interaction and generative AI-powered summarization. The ability to query dashboards using plain English questions (e.g., “What’s the root cause of the slowdown in the payment service?”) or to receive AI-generated, concise summaries of complex incidents will be pivotal. These advancements will make the rich insights from AIOps systems even more intuitive and accessible to a broader range of IT professionals, further reducing cognitive load and accelerating response times. This trend aligns with the broader movement of embedding Generative AI capabilities within enterprise software to enhance user experience and productivity.
Navigating the AIOps Journey: Implementation, Challenges, and Best Practices
Embarking on an AIOps journey is a strategic undertaking that requires careful planning, robust data practices, the right technology, skilled personnel, and a willingness to embrace cultural change. Organizations must navigate several key considerations and potential pitfalls to realize the full benefits of AIOps.
Key Considerations for AIOps Adoption:
- Data Strategy is Paramount:
- Data Quality and Completeness: AIOps is fundamentally data-driven. The accuracy and efficacy of AI/ML models depend entirely on the quality of the data they are fed. Inaccurate, incomplete, inconsistent, or poorly contextualized data will inevitably lead to flawed analyses, unreliable predictions, and ineffective automation. Therefore, establishing strong data governance practices, along with processes for data cleansing, normalization, and enrichment, is a critical prerequisite.
- Comprehensive Data Integration: AIOps platforms need to ingest and correlate data from a wide array of diverse and often siloed sources. This includes logs, metrics, traces, events from monitoring tools, configuration data from CMDBs, incident data from ITSM systems, and potentially network topology and business application data. A centralized data aggregation strategy or a data lake architecture is often essential to break down these silos and provide a unified data foundation for AIOps.
- Platform Selection Criteria: Choosing the right AIOps platform is a crucial decision. Evaluation should be based on a comprehensive set of criteria:
- Data Ingestion Capabilities: The platform’s ability to connect to and ingest data from a broad range of sources and formats, including legacy systems and modern cloud-native technologies.
- AI/ML Analytics Capabilities: The sophistication and breadth of its AI/ML algorithms for core functions like advanced anomaly detection (dynamic baselining, outlier detection), intelligent event correlation, cross-domain pattern recognition, predictive analytics, and automated root cause analysis.
- Integration Ecosystem: The ease and extent of out-of-the-box integrations with existing monitoring tools, ITSM platforms (like ServiceNow or Jira Service Management), automation engines, and communication tools (like Slack or Microsoft Teams).
- Automation and Orchestration: Robust capabilities for triggering automated remediation actions, orchestrating complex workflows, and integrating with runbook automation tools.
- Scalability and Performance: The platform’s architecture must be able to scale to handle ever-increasing data volumes and the computational demands of real-time analysis in large, dynamic environments.
- Usability and Explainability (XAI): An intuitive user interface for operators and analysts, coupled with features that provide transparency and explanations for AI-driven decisions and recommendations. Explainable AI is vital for building trust and enabling users to understand and validate AIOps outputs.
- Vendor Support, Roadmap, and Vision: The vendor’s reputation for customer support, their long-term product vision, commitment to innovation (e.g., integration of Generative AI), and alignment with the organization’s strategic goals are important factors. Forrester Wave AIOps platform evaluations can provide valuable third-party assessments.
- Building the Right Team Skills: Successful AIOps implementation and operation require a blend of diverse expertise. This includes traditional IT operations knowledge, data science and AI/ML skills for model development and tuning, automation engineering capabilities, and Site Reliability Engineering (SRE) principles for managing complex systems with a focus on reliability and efficiency. Organizations often need to invest in upskilling their existing IT teams and may also need to hire specialized talent.
Overcoming Common Implementation Pitfalls:
Despite the promise of AIOps, organizations often encounter challenges during implementation :
- Fragmented Data Silos: As mentioned, this is a primary obstacle. It is best addressed by prioritizing centralized data integration and establishing robust data governance from the outset.
- Complexity of IT Ecosystems: Modern IT environments are inherently complex. A recommended approach is to start with a pilot program focused on a specific, well-defined use case with clear success metrics. This allows the team to gain experience, demonstrate value, and then incrementally expand AIOps capabilities across the organization. Choosing scalable and adaptable AIOps platforms is also key.
- High Initial Costs: The investment in AIOps platforms, infrastructure, and specialized skills can be significant. To manage this, organizations can explore leveraging open-source tools for initial phases or proof-of-concepts, and should prioritize use cases that deliver quick, measurable ROI, such as significant MTTR reduction or operational cost savings.
- Alert Fatigue from AIOps Itself: Ironically, poorly configured or immature AIOps systems can sometimes generate their own noise or false positives. This necessitates continuous fine-tuning of AI/ML algorithms, adjustment of sensitivity thresholds, and leveraging the platform’s continuous learning capabilities to improve accuracy over time and minimize false alerts.
The Critical Role of Cultural Change and Building Trust in AI:
Perhaps one of the most significant, yet often underestimated, aspects of AIOps adoption is managing the cultural shift within IT operations :
- Resistance to Change: IT teams accustomed to traditional, manual ways of working may exhibit resistance. This can stem from a fear of job displacement due to automation, skepticism about the reliability or decision-making capabilities of AI, or simply discomfort with new tools and processes.
- Strategies for Fostering Adoption and Trust:
- Clear and Consistent Communication: Articulate the benefits of AIOps not just for the business, but also for the IT teams themselves – how it can reduce toil, eliminate repetitive tasks, and allow them to focus on more engaging and strategic work.
- Early and Inclusive Involvement: Engage IT teams early in the AIOps strategy development and platform selection process. Their input is invaluable, and early involvement fosters a sense of ownership and reduces resistance.
- Comprehensive Training and Upskilling: Invest in hands-on training to ensure teams are comfortable and proficient with new AIOps tools and concepts. This builds confidence and demonstrates a commitment to their professional development.
- Phased Rollout with AI Assistance First: Begin by deploying AIOps in an assistive capacity, providing insights and recommendations that human operators can validate and act upon. Gradually introduce more automation as trust in the system’s capabilities grows.
- Establish Governance and Human Oversight: Implement clear governance policies for AI-driven actions, ensuring that there are always mechanisms for human oversight, review, and intervention, especially for critical changes. This is crucial for building trust and mitigating risks.
- Highlight Successes and Iterate: Showcase early wins from pilot projects to build momentum and demonstrate the value of AIOps. Use feedback from these initial phases to refine the strategy and continuously improve. Forrester emphasizes the importance of aligning AIOps initiatives with tangible business outcomes and ensuring broad stakeholder agreement to drive success.
The journey to AIOps is as much a data and people transformation as it is a technological one. The rigorous data quality and integration requirements inherent in AIOps can serve as a powerful catalyst, compelling organizations to improve their data management practices across the entire IT landscape. Similarly, the demand for new skills often drives investment in comprehensive training and development programs, which can upskill the workforce for a variety of modern IT challenges, not just AIOps. Successfully navigating the cultural shift towards AI-driven automation can also pave the way for other strategic AI initiatives within the broader enterprise. In this sense, AIOps is not merely an endpoint but a significant step in an ongoing evolution towards more intelligent, agile, and autonomous IT operations, fostering a culture of continuous improvement and innovation.
The Future is Autonomous: AIOps, Generative AI, and Self-Healing Systems
The field of AIOps is continuously evolving, driven by advancements in artificial intelligence and the ever-increasing demands of digital business. The future points towards increasingly autonomous IT operations, with Generative AI and the pursuit of self-healing systems playing pivotal roles.
The Expanding Role of Generative AI in Enhancing AIOps:
Generative AI, with its ability to create new content, code, and human-like text, is poised to significantly enhance AIOps capabilities and user experience :
- Natural Language Interaction: Future AIOps platforms will increasingly allow operators to interact with systems using natural language queries (e.g., “What were the top causes of network latency last night?”) and receive incident summaries or explanations in plain, understandable language. This lowers the barrier to accessing complex information.
- Automated Report and Documentation Generation: Generative AI can automate the creation of detailed incident reports, update knowledge base articles with learnings from recent events, and even generate initial drafts of runbook procedures based on observed patterns and resolutions. BigPanda, for instance, notes that Generative AI can assist in converting existing runbooks into more dynamic, AI-driven playbooks using Large Language Models (LLMs).
- Intelligent Runbook Creation and Suggestion: Beyond just documenting, Generative AI can dynamically generate or suggest contextually relevant remediation steps during an active incident, drawing from a vast corpus of historical data, best practices, and real-time system state.
- Enhanced Root Cause Analysis Summaries: Generative AI can synthesize complex technical findings from an RCA process into concise, human-readable summaries, making it easier for diverse teams, including business stakeholders, to understand the implications of an incident.
- Code Generation for Automation Scripts: For IT teams developing custom automation, Generative AI can assist in generating boilerplate code or suggesting code snippets for automation scripts, accelerating the development of remediation workflows.
Industry analysts like BigPanda predict that Generative AI will unlock significant value by enabling AIOps to leverage previously untapped unstructured data sources (like wikis, chat logs, and external documentation) for even richer insights and more sophisticated automation. Gartner projects that by 2026, over 80% of enterprises will have utilized Generative AI APIs and models or deployed GenAI-enabled applications in production environments, a massive leap from less than 5% in 2023.
The Evolution Towards Truly Self-Healing IT Environments:
AIOps is a critical stepping stone on the path to truly autonomous, self-healing IT environments. The vision is for systems that can automatically and proactively detect, diagnose, and resolve a wide range of issues with minimal, or in some cases, no human intervention.
This evolution involves the deployment of sophisticated AI agents that can autonomously execute complex resolution workflows across the entire IT stack – from infrastructure and middleware to applications and data layers. These agents would continuously monitor the environment, learn from its behavior, predict potential failures, and initiate corrective actions to maintain stability and performance. ScienceLogic articulates this future as “Autonomic IT,” where agentic AI transitions from being a reactive assistant to a proactive advisor and, ultimately, an autonomous actor.
Predictions for AIOps Market Trends:
The AIOps market itself is dynamic and expected to see continued evolution :
- Market Consolidation: As the AIOps landscape matures, there is a trend towards organizations seeking comprehensive, integrated AIOps platforms that consolidate a wide range of functions, including advanced monitoring, deep analytics, and intelligent automation, rather than relying on a patchwork of niche tools.
- Deeper and Broader Integrations: AIOps capabilities will become more deeply embedded within broader IT ecosystems and enterprise workflows, including ITSM, DevOps toolchains, security operations (SecOps), and even business process management.
- Increased Sophistication of Automation: The push for efficiency and resilience will continue to drive the development and adoption of more sophisticated automation capabilities, moving from simple scripted responses to AI-driven, context-aware, and adaptive automation.
- Democratization of AIOps: Driven by advancements like Generative AI and more intuitive user interfaces, AIOps capabilities will become more accessible to a wider range of IT professionals, not just specialized data scientists or AI experts.
Generative AI, in particular, is poised to significantly lower the barrier to entry for AIOps and dramatically improve the user experience, thereby accelerating its adoption and impact. By enabling natural language interactions for querying complex systems and automating knowledge-intensive tasks like report generation or initial runbook drafting , Generative AI can make AIOps tools more intuitive, reduce the need for deep specialized skills for certain tasks, and ultimately democratize access to powerful operational insights. This wider accessibility can drive broader adoption across organizations of all sizes and levels of AI maturity.
However, the ambitious pursuit of truly self-healing systems, while technologically enticing, will necessitate a fundamental rethinking of IT governance, risk management frameworks, and the ethical considerations surrounding AI autonomy in critical operational contexts. As AIOps systems gain greater autonomy to “act” upon the IT environment – potentially making changes that could have significant impact – critical questions around accountability for AI-driven decisions, the potential for unintended consequences from automated actions, and the appropriate level of human oversight in high-stakes scenarios become paramount. Organizations will need to proactively develop and implement robust frameworks for “Responsible AI” within their IT operations, ensuring that principles of transparency, fairness, security, and accountability are embedded into their AIOps strategies and systems. This goes beyond technical implementation to address the broader societal and business implications of increasingly autonomous IT.
Conclusion: Embracing AIOps for a Resilient and Efficient Future
The journey through the landscape of modern IT operations reveals a clear and compelling narrative: AIOps is not just an incremental improvement but a revolutionary force reshaping how organizations manage complexity, ensure service reliability, and drive digital innovation. By intelligently harnessing the power of big data, machine learning, and automation, AIOps is fundamentally transforming both incident management and observability.
In incident management, AIOps has moved the needle from reactive firefighting to proactive prevention. It achieves this through intelligent alert correlation that cuts through the noise, automated root cause analysis that drastically reduces MTTR, predictive capabilities that anticipate issues before they impact users, and automated remediation that paves the way for self-healing systems. The result is significantly reduced downtime, improved operational efficiency, and IT teams that are less burdened by toil and more focused on strategic initiatives.
In the realm of observability, AIOps elevates the practice from passive data collection to active, intelligent system understanding. It supercharges the traditional pillars of metrics, logs, and traces with advanced anomaly detection, cross-domain pattern recognition, and contextual data enrichment. This provides deeper, more actionable insights into system behavior, enabling a holistic view of the entire IT stack and fostering a more profound understanding of how systems perform and interact. The synergy between AIOps and observability creates a virtuous cycle, where better data fuels smarter insights, and smarter insights refine data collection, leading to continuous improvement and operational excellence.
The real-world success stories and diverse use cases presented underscore that AIOps is delivering tangible benefits across industries – from dramatic reductions in incident resolution times and operational costs in financial services to enhanced service reliability in technology and supply chain sectors. These are not abstract technological gains; they translate directly into improved customer experiences, greater business agility, and a stronger competitive posture.
Looking ahead, the integration of Generative AI promises to make AIOps even more intuitive, accessible, and powerful, further accelerating the journey towards highly autonomous and self-healing IT environments. However, this journey also requires careful consideration of data strategies, platform choices, team skills, and, crucially, the cultural shifts necessary to embrace AI-driven operations.
The evidence strongly suggests that AIOps is no longer a niche technology or a futuristic concept; it is a strategic imperative for any organization seeking to thrive in the complex, fast-paced digital age. The ability to manage intricate IT environments effectively, ensure unwavering business continuity, and free up resources to enable digital innovation is paramount. Organizations are encouraged to assess their operational maturity, identify high-impact use cases to begin their AIOps journey, invest in the foundational pillars of data quality and team skills, and proactively manage the cultural evolution. By embracing AIOps, businesses can build not just more resilient and efficient IT operations, but a more intelligent and adaptive foundation for their future success.